ChaCha and Vector Registers
“If you were plowing a field, which would you rather use: two strong oxen or 1024 chickens?”
A stream cipher generates a long stream of random-looking numbers (called a keystream) and XORs them with data to encrypt or decrypt. ChaCha is a widely used stream cipher that appears in many modern cryptographic systems, including TLS, WireGuard and secure messaging protocols.
One of the defining properties of counter-based stream ciphers like ChaCha and AES-CTR is how cleanly they parallelise:
every “block” of the keystream can be calculated independently.
In this short post we’ll explore how this mathematical property interacts with the physical architecture of modern CPUs, and show that a modification to the implementation of Rust Crypto can lead to a significant improvement (almost 50%) in throughput performance for ChaCha.
Vector registers
Since the frequency scaling plateau of the mid-2000s, improvements in CPU performance no longer come primarily from higher clock speeds. Instead, CPUs scale mostly through increased parallelism. Inside a single CPU core, there are two key forms of this:
- Instruction-level parallelism (ILP): Executing multiple independent instructions at the same time (via e.g. superscalar execution and instruction pipelining).
- Single instruction, multiple data (SIMD): Applying one instruction to a “vector” of multiple data elements simultaneously.
In the latter case, these vectors are processed in “vector registers”: instead of holding a single scalar value, these registers pack multiple values in a single unit and apply the same instruction across all of them simultaneously. In modern architectures, these registers are usually at least 128 bits wide.
ChaCha blocks
Each ChaCha block consists of 64 bytes (512 bits) of keystream, which are derived from
- a 128-bit constant
- a 256-bit key
- a nonce
- a block counter
These inputs are arranged into a 4×4 matrix of 32-bit words and then “scrambled” through several rounds (usually 20) of ARX operations:
- Addition (mod $2^{32}$),
- Rotation (bitwise rotation)
- XOR
These operations are deliberately chosen because:
- they map directly onto fast integer instructions on modern CPUs, which are usually executed in a single cycle
- they avoid memory lookups
- they run in constant time, making them resistant to timing attacks
More specifically, each ChaCha round consists of four “quarter rounds”, and each of those operates on four 32-bit words $(a,b,c,d)$ as follows:
\[\begin{aligned} a &\mathrel{+}= b \quad & d &\mathrel{\oplus}= a \quad & d &\lll= 16 \\ c &\mathrel{+}= d \quad & b &\mathrel{\oplus}= c \quad & b &\lll= 12 \\ a &\mathrel{+}= b \quad & d &\mathrel{\oplus}= a \quad & d &\lll= 8 \\ c &\mathrel{+}= d \quad & b &\mathrel{\oplus}= c \quad & b &\lll= 7 \end{aligned}\]This algorithm was designed with vector registers in mind: since those are at least 128 bits wide, a single register can easily hold four 32-bit words. Hence the four quarter rounds of a round can be run in parallel.
In Rust Crypto a ChaCha block is thus implemented as an array of 4 vector registers, and the four quarter rounds are implemented as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
unsafe fn add_xor_rot<const N: usize>(blocks: &mut [[uint32x4_t; 4]; N]) {
for block in blocks.iter_mut() {
// a += b; d ^= a; d <<<= 16;
add_assign_vec!(block[0], block[1]);
xor_assign_vec!(block[3], block[0]);
rotate_left!(block[3], 16);
// c += d; b ^= c; b <<<= 12;
add_assign_vec!(block[2], block[3]);
xor_assign_vec!(block[1], block[2]);
rotate_left!(block[1], 12);
// a += b; d ^= a; d <<<= 8;
add_assign_vec!(block[0], block[1]);
xor_assign_vec!(block[3], block[0]);
rotate_left!(block[3], 8);
// c += d; b ^= c; b <<<= 7;
add_assign_vec!(block[2], block[3]);
xor_assign_vec!(block[1], block[2]);
rotate_left!(block[1], 7);
}
}
Because the ARX operations need to apply to columns in one half of the round and diagonals in the other, the implementation uses cheap in-register SIMD lane shuffles (vextq_u32) to realign the data without moving data through memory; these are the rows_to_cols and cols_to_rows transformations in the codebase.
These ARX operations stand in stark contrast to ciphers like AES. ChaCha20 only requires addition, XOR, and rotation operations, all of which map efficiently onto ordinary SIMD instructions. AES, on the other hand, achieves its best performance using dedicated hardware support such as AES-NI on x86 or ARM Crypto Extensions. While software-only AES implementations are possible, they are typically slower and have been harder to implement in a constant-time manner.
To summarise, ChaCha’s design maps naturally onto 128-bit vector registers, which can each hold four 32-bit words: it uses four registers to do “vertical SIMD” for each of the four words in a quarter round. But there are usually more than four vector registers; typically there are 16 or 32. So
instead of computing one block, one can compute several blocks at the same time.
Thus for ChaCha, SIMD gives us two distinct layers of parallelism:
Within a block:
A vector register can hold multiple 32-bit words, allowing the quarter rounds of a single ChaCha block to be processed in parallel (using 4 vector registers).Across blocks:
Because blocks are independent, we can pack multiple ChaCha blocks into the vector registers and process them simultaneously.
This SIMD-friendly software performance was one of the major reasons ChaCha20 became popular on mobile devices, especially before ARM CPUs widely adopted dedicated AES acceleration instructions.
NEON registers
On AArch64 (used by Apple silicon, AWS Graviton and most mobile CPUs), SIMD is provided by NEON registers:
- 32 vector registers
- Each register is exactly 128 bits wide
This is enough register capacity to process roughly $ 32 / 4 = 8$ ChaCha blocks in parallel without significant register pressure. If you try to use more registers, the compiler may spill values to system memory, which is very slow. On the other hand, if you only process say 4 blocks in parallel, then you’re only using 16 vector registers and the remaining 16 vector registers are mostly sitting idle.
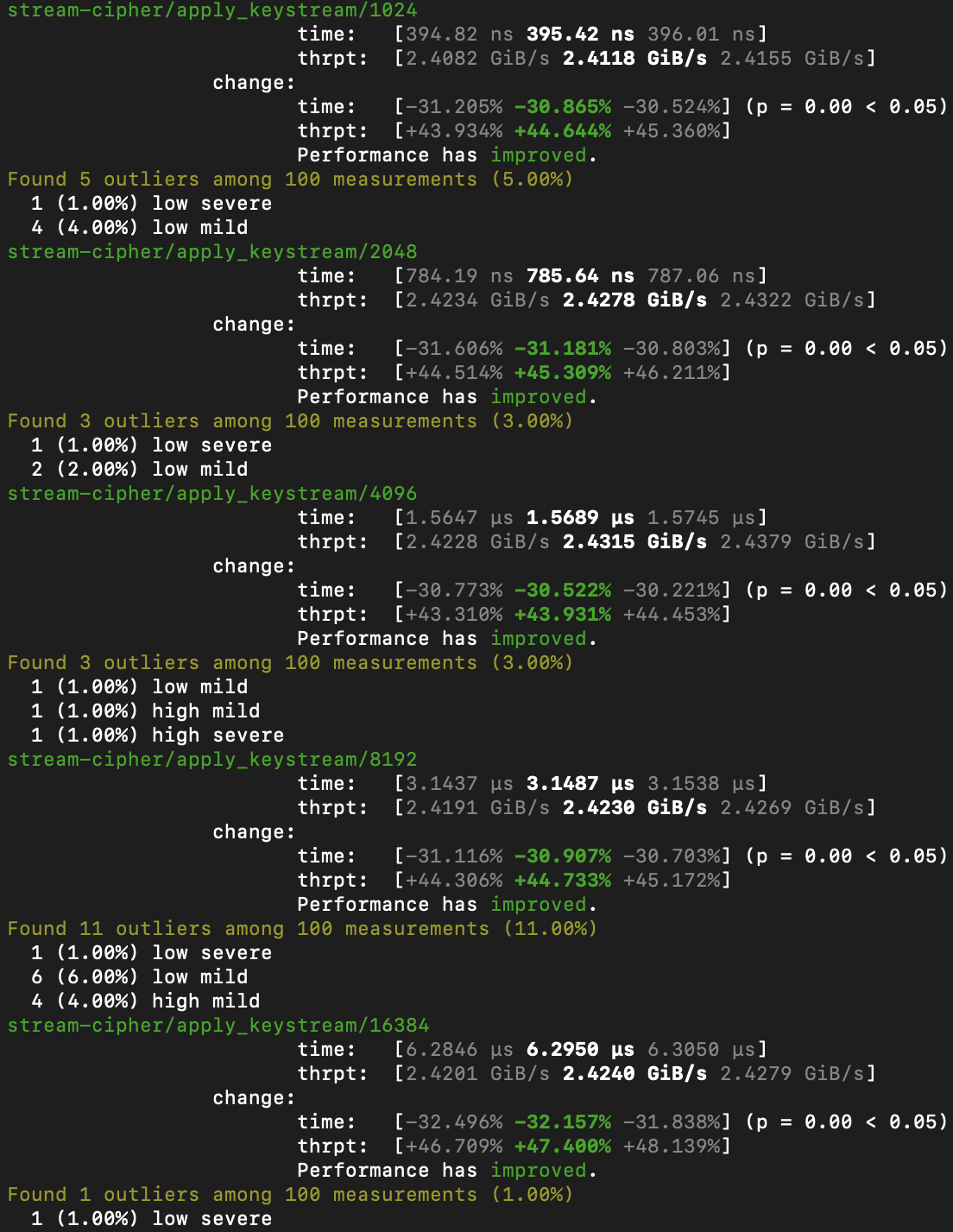
Implementation
Until recently, RustCrypto’s ChaCha20 implementation processed 4 blocks in parallel on NEON, leaving a significant portion of SIMD capacity unused. This simple PR increases that to 8 parallel blocks, matching the architectural limit much more closely. On an Apple M4 Max, this change results in an almost 50% improvement in throughput performance: